Les accidents de la circulation de 2005 à 2016 visualisés avec R
Vincent Brouté • November 14, 2017
dataEn plein apprentissage de R, je vais essayer de mettre en pratique mes connaissances nouvellement acquises au travers d’une mini-étude basique sur les données des accidents corporels de la circulation en France entre 2005 et 2016. Mon objectif n’est pas d’étudier en profondeur ces données (cela demanderait beaucoup plus de temps, d’analyses et de croisements avec d’autres informations !), mais simplement d’approfondir l’utilisation de certains packages R, notamment {ggplot2} et {ggmap} pour les charts. Comme c’est en faisant des erreurs que l’on apprend, n’hésitez pas à me faire part via les commentaires des éventuelles coquilles que vous pourriez déceler. Tentons donc de mettre en exergue quelques tendances sur les accidents de la route …
Le code source (au format R Markdown) est disponible sur Github. Si vous voulez en apprendre davantage sur les différents packages utilisés ({readr}, {dyplr}, {ggplot2}, etc), n’hésitez pas à jeter un œil au très bon livre R for data science.
Les données des accidents de la circulation sont publiés en Open Data sur la plateforme data.gouv.fr . Commençons par apporter quelques précisions sur ces données :
- Elles ne concernent que les accidents corporels de la circulation, c’est-à-dire les accidents “survenus sur une voie ouverte à la circulation publique, impliquant au moins un véhicule et ayant fait au moins une victime ayant nécessité des soins” (donc exit tous les petits accrocs sans gravité)
- Les données couvrent 12 années allant de 2005 à 2016
- Pour un accident, les informations sont réparties au travers de 4 jeux de données distincts : on a ses caractéristiques, les véhicules impliqués, les usagers ainsi que des détails sur le lieu
- Les données sont réparties en 48 datasets et totalisent 4 989 364 observations
Import et nettoyage des données
Avant toute manipulation ou visualisation des données, il faut au préalable les importer et les nettoyer. J’ai d’abord commencé à explorer les accidents en important les 4 datasets d’une année en particulier. Cette méthode fonctionne bien lorsque l’étude porte sur quelques jeux de données, mais quand il s’agit d’explorer un grand nombre de fichiers, comme par exemple dans notre cas avec les 48 datasets des accidents, il faut réfléchir à un moyen d’automatiser les imports.
Sur data.gouv.fr, la liste des fichiers d’un jeu de données (et leurs métadonnées comme la date de dernière modification, etc) est disponible au format RDF sous différentes sérialisations : RDF/XML, Turtle, JSON-LD, Trig ou encore N3. On peut retrouver toutes ces versions dans les <link rel="alternate" ...> dans la source de la page du jeu de données. On va exploiter la version JSON-LD avec le package {jsonlite}.
Voici un aperçu des informations qui nous intéressent dans ce JSON-LD :
datasetsList <- fromJSON('https://www.data.gouv.fr/datasets/53698f4ca3a729239d2036df/rdf.json')$\`@graph\` %>%
select(title, downloadURL) %>%
filter(str\_detect(title, 'caracteristiques\_|lieux\_|usagers\_|vehicules\_'))
 Contenu de datasetsList
Contenu de datasetsList
Cette collection va donc permettre d’importer facilement tous les datasets de façon automatisée. L’objectif est d’obtenir in fine un data.frame pour chacune des 4 catégories de données : caractéristiques, véhicules, usagers et lieux. Chaque data.frame contiendra ainsi la fusion de toutes les années de données disponibles. J’ai créé une fonction nommée importDatasetsByTitle() qui va nous permettre d’importer et de fusionner tous les fichiers d’accidents en les filtrant par leurs titres (thématiques) :
_#' Returns a data.frame that contains all the rows from the data files for a specific dataset provided by the data.gouv.fr platform_
_\# All the rows from the datasets whose the titles match 'titleFilter' will be merged together_
_#' @param datasetId The dataset ID from data.gouv.fr. It can be found within the source code of the dataset page within the "@id" attribute_
_#' @param titleFilter The string for filtering the datasets titles in order to select only the relevant ones_
_#' @param colTypes The column specification created through cols()_
_#' @param delim Single character used to separate fields within a record_
_#' @param stringLocale The datasets locale_
_#' @return The data.frame for the specified accidents category_
importDatasetsByTitle <- **function**(datasetId, titleFilter, colTypes, delim = ',', stringLocale = locale(encoding = "Latin1")) {
filteredDatasets <- fromJSON(paste('https://www.data.gouv.fr/datasets/', datasetId, '/rdf.json', sep=''))$\`@graph\` %>%
select(title, downloadURL) %>%
filter(str\_detect(title, titleFilter)) %>%
mutate(dataset = map2(downloadURL, delim, read\_delim, locale = stringLocale, col\_types = colTypes))
bind\_rows(filteredDatasets$dataset)
}
Note : La fonction importDatasetsByTitle() peut tout à fait être utilisée pour importer et fusionner d’autres jeux de données sur datagouv.fr.
Les fichiers sont globalement propres, mais j’ai tout de même noté ces quelques points :
- Un seul des 48 fichiers,
caracteristiques_2009.csv, est au format TSV, allez comprendre pourquoi … - Les dates sont dispersées sur 4 colonnes :
an,mois,jourethhmm - Les heures et minutes des accidents sont concaténées dans une seule colonne, avec omission des
0devant les heures de 00 à 09 et devant les minutes de 01 à 09. La documentation n’étant pas claire sur ce point, il faut donc à priori faire notre propre interprétation lorsque l’on est face à des valeurs du type ‘45’ : s’agit-il de 04:05 ou de 04:50 ? Ou encore la valeur ‘1’ correspond à 00:01 ou à 01:00 ? Dans ce cas, j’ai considéré qu’il s’agissait d’heures (‘1’ = 01:00). Cela explique notamment pourquoi dans les graphiques par heures, il n’y a aucun accident entre minuit et 1h ... J’espère que cette colonne sera rapidement corrigée !
La fonction toDate() va nous permettre de reconstruire un objet datetime à partir des différentes variables :
#' Convert year, month, day and hm variables into a valid date object
#' [@param](http://twitter.com/param) year
#' [@param](http://twitter.com/param) month
#' [@param](http://twitter.com/param) day
#' [@param](http://twitter.com/param) hm concatenated hours and minutes
toDate <- function(year, month, day, hm) {
date <- str\_c('20', str\_pad(year, 2, "left", "0"), '-', str\_pad(month, 2, "left", "0"), '-', str\_pad(day, 2, "left", "0"), ' ')
if (str\_length(hm) == 1) {
hm <- str\_c('0', hm, ':00')
} else if (str\_length(hm) == 2) {
hm <- str\_c('0', str\_sub(hm, 1, 1), ':0', str\_sub(hm, 2, 2))
} else if (str\_length(hm) == 3 && str\_sub(hm, 1, 1) != 0) {
hm <- str\_c('0', str\_sub(hm, 1, 1), ':', str\_sub(hm, 2, 3))
} else if (str\_length(hm) == 3 && str\_sub(hm, 1, 1) == 0) {
hm <- str\_c(str\_sub(hm, 1, 2), ':0', str\_sub(hm, 3, 3))
} else {
hm <- str\_c(str\_sub(hm, 1, 2), ':', str\_sub(hm, 3, 4))
}
str\_c(date, ' ', hm)
}
\# Note : il est sûrement possible de faire quelque chose de plus propre et de plus optimisé pour formater les heures et minutes correctement ...
Importons maintenant les données pour chacune des 4 thématiques :
datasetId <- '53698f4ca3a729239d2036df'specificationsCols <- cols(
Num\_Acc = col\_character(),
com = col\_character(),
lat = col\_double(),
long = col\_double(),
dep = col\_character()
)
accidentsSpecifications <- importDatasetsByTitle(datasetId, 'caracteristiques\_(?!2009)', specificationsCols) _\# Handle 2009 file (in TSV format ...)_
accidentsSpecifications2009 <- read\_delim(
'https://www.data.gouv.fr/s/resources/base-de-donnees-accidents-corporels-de-la-circulation/20160422-111851/caracteristiques\_2009.csv',
'\\t',
locale = locale(encoding = "Latin1"),
col\_types = specificationsCols
)
accidentsSpecifications <- bind\_rows(accidentsSpecifications, accidentsSpecifications2009)_\# Add some alternative date formats to accidentSpecifications data.frame, it will be needed for the charts below_
accidentsSpecifications <- mutate(accidentsSpecifications,
datetime = ymd\_hm(pmap(list(an, mois, jour, hrmn), toDate)),
date = as.Date(datetime),
year = year(date),
wday = wday(date, label = TRUE),
hour = hour(datetime),
weekdayshours = update(datetime, year = 2017, month = 01, day = wday(date), minute = 0)
)accidentsLocations <- importDatasetsByTitle(
datasetId,
'lieux\_',
cols(
Num\_Acc = col\_character(),
voie = col\_character(),
v1 = col\_character()
)
) %>% inner\_join(accidentsSpecifications, by = "Num\_Acc")accidentsUsers <- importDatasetsByTitle(
datasetId,
'usagers\_',
cols(
Num\_Acc = col\_character(),
secu = col\_character()
)
) %>% inner\_join(accidentsSpecifications, by = "Num\_Acc")
accidentsVehicles <- importDatasetsByTitle(
datasetId,
'vehicules\_',
cols(
Num\_Acc = col\_character()
)
) %>% inner\_join(accidentsSpecifications, by = "Num\_Acc")
Maintenant que nous avons chargé les données dans des data.frame, essayons d’en visualiser quelques grandes tendances.
Evolution du nombre d’accidents et du nombre de morts sur la route
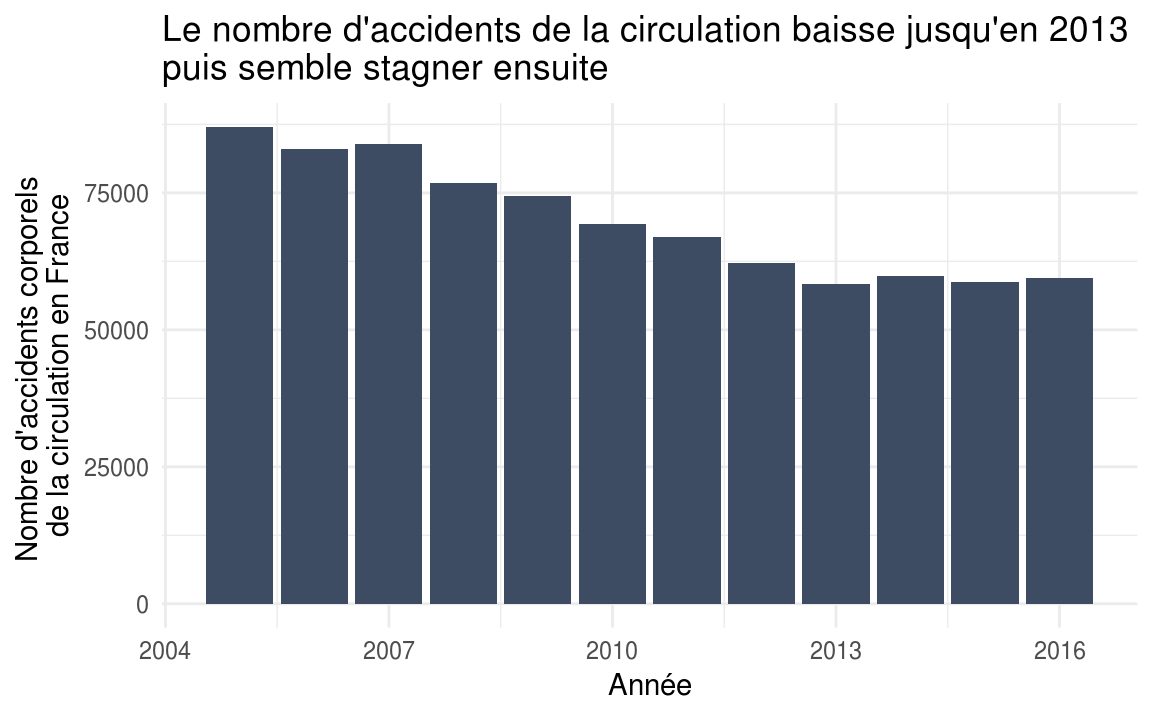
accidentsSpecifications %>%
ggplot(aes(x = year)) +
geom\_bar(fill = "#3e4c63") +
labs(
title = "Le nombre d'accidents de la circulation baisse jusqu'en 2013 \\npuis semble stagner ensuite",
x = "Année",
y = "Nombre d'accidents corporels de la circulation en France"
) +
theme\_minimal()
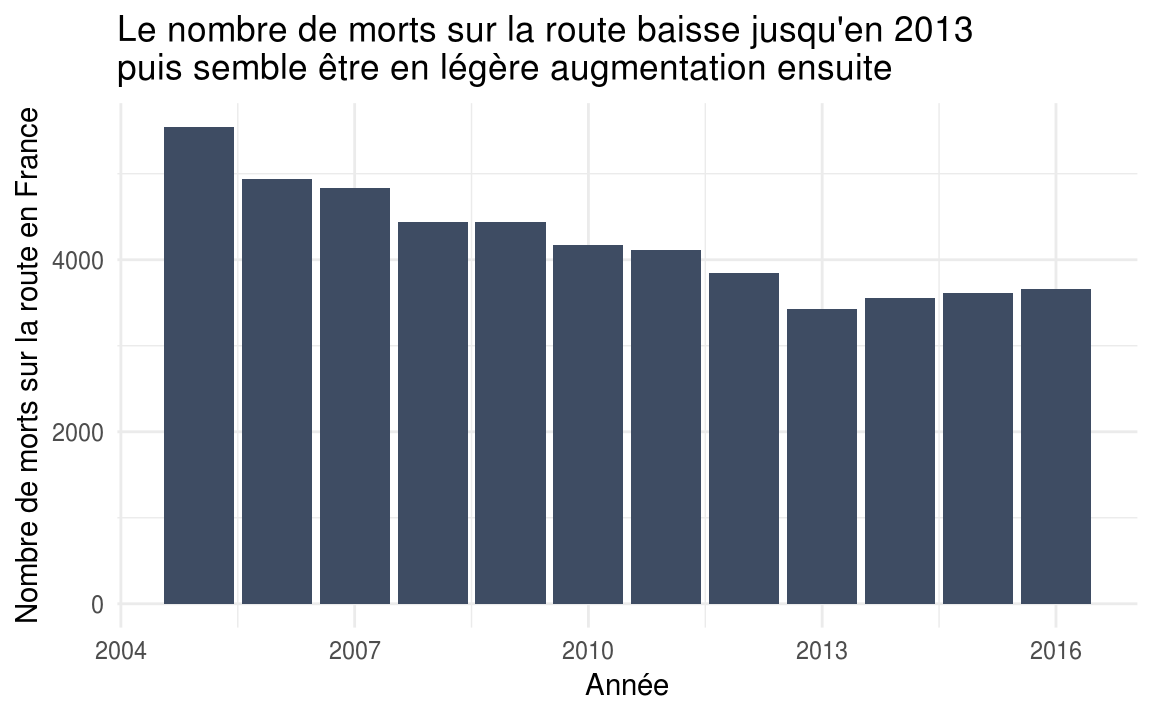
accidentsUsers %>%
filter(grav == 2) %>%
ggplot(aes(x = year)) +
geom\_bar(fill = "#3e4c63") +
labs(
title = "Le nombre de morts sur la route baisse jusqu'en 2013 \\npuis semble être en légère augmentation ensuite",
x = "Année",
y = "Nombre de morts sur la route en France"
) +
theme\_minimal()
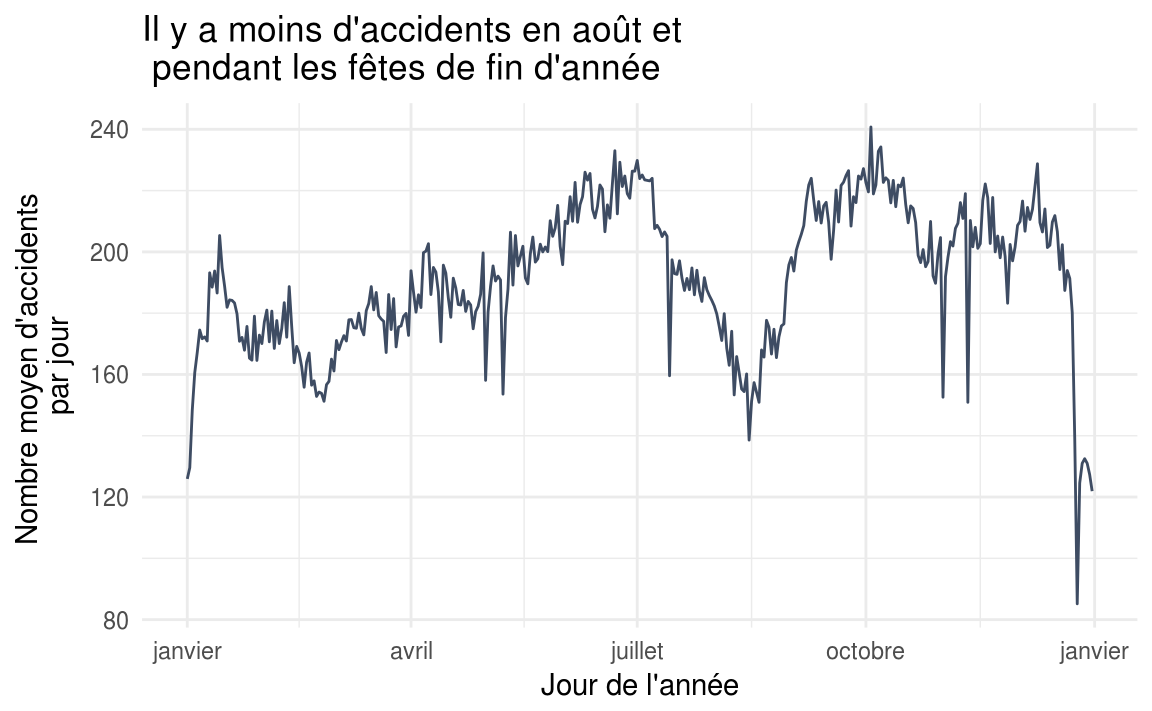
accidentsSpecifications %>%
group\_by(date) %>%
summarize(nb\_accidents = n()) %>%
mutate(date = update(date, year = 2017)) %>%
group\_by(date) %>%
summarize(nb\_accidents = mean(nb\_accidents)) %>%
ggplot(aes(x = date, y = nb\_accidents, group = 1)) +
geom\_line(color = "#3e4c63") +
labs(
title = "Il y a moins d'accidents en août et pendant les fêtes de fin d'année",
x = "Jour de l'année",
y = "Nombre moyen d'accidents par jour"
) +
theme\_minimal() +
scale\_x\_date(date\_labels = "%B")
top10 <- accidentsSpecifications %>%
group\_by(date) %>%
summarize(nb\_accidents = n()) %>%
mutate(date = update(date, year = 2017)) %>%
group\_by(date) %>%
summarize(nb\_accidents = mean(nb\_accidents)) %>%
arrange(nb\_accidents) %>%
filter(row\_number() <= 10)

Top 10 des jours de l’année avec, en moyenne, le moins d’accidents
Attention, cela ne veut pas forcément dire que les usagers de la route sont plus prudents pendant les vacances. On peut supposer notamment qu’il y globalement moins de circulation durant le mois d’août par rapport au reste de l’année, et ce, malgré les pics de départs et retours de vacances. On peut voir que c’est bien le cas à Paris si l’on en croit cet article publié sur francebleu.fr : “Paris au mois d’août : ça roule mieux”. Pour pouvoir confirmer ce point, il faudrait cependant se reposer sur une véritable étude, ou pa exemple exploiter des statistiques provenant d’applications comme Waze si elles venaient à être mise à disposition.
Il est également intéressant d’observer cette courbe par département. On peut voir par exemple qu’en été, le nombre d’accidents baisse sensiblement à Paris alors que dans la même période, il augmente dans le var.
Accidents et morts en fonction de l’heure de la journée et du jour de la semaine
dayHours <- c(7:23, 0:6)
dayHoursLabels <- c('07', '08', '09', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '00', '01', '02', '03', '04', '05', '06')accidentsSpecifications %>%
mutate(datetime = update(datetime, minutes = 0, seconds = 0)) %>%
group\_by(datetime) %>%
summarize(nb\_accidents = n()) %>%
mutate(hour = hour(datetime)) %>%
group\_by(hour) %>%
summarize(nb\_accidents = mean(nb\_accidents)) %>%
mutate(hour = factor(hour, levels = dayHours, labels = dayHoursLabels)) %>%
ggplot(aes(x = hour, y = nb\_accidents, group = 1)) +
geom\_col(fill = "#3e4c63") +
labs(
title = "Il y a plus d'accidents de la circulation entre 17h et 19h",
x = "Heure de la journée",
y = "Nombre moyen d'accidents par heure"
) +
theme\_minimal()
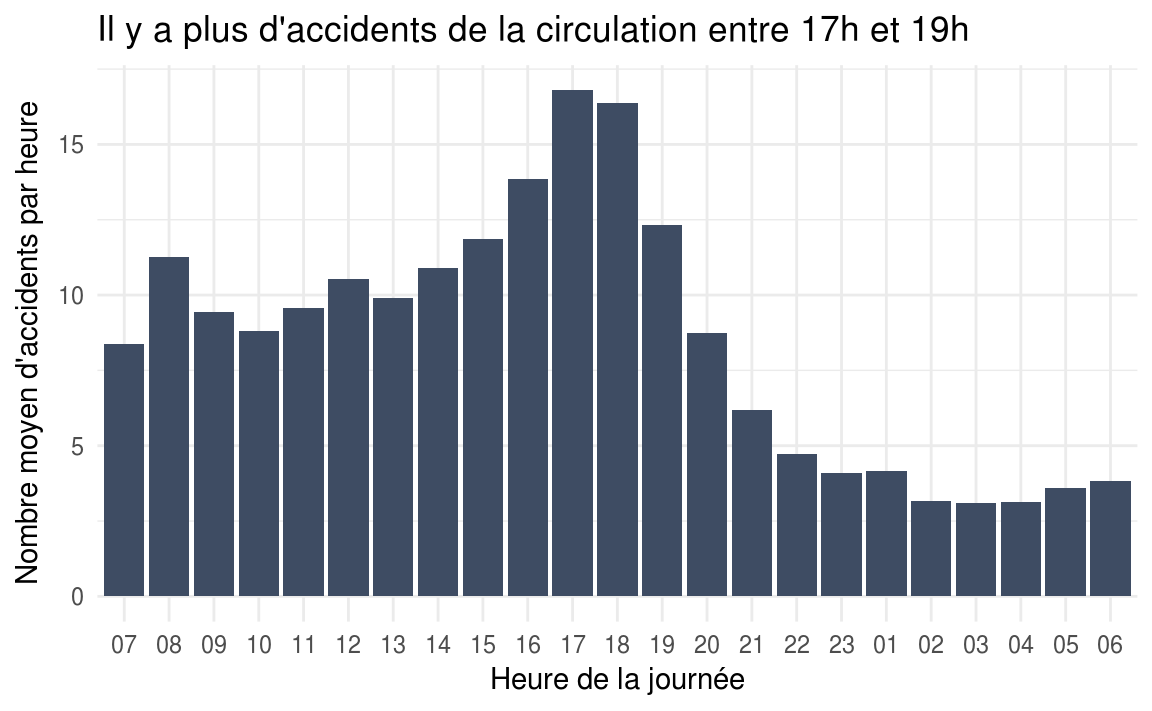
On voit un premier pic entre 8h et et 10h, puis un second beaucoup plus prononcé entre 17h et 19h. On peut supposer que ces pics correspondent aux allers et retours entre le domicile et le lieu de travail pendant lesquels le nombre de véhicules en circulation est globalement beaucoup plus important que sur le reste de la journée.
Il serait intéressant de comprendre pourquoi le pic des retours est beaucoup plus important que le pic des allers.
inner\_join(
accidentsUsers %>%
filter(grav == 2) %>%
group\_by(hour) %>%
summarize(nb\_deathlyaccidents = n\_distinct(Num\_Acc)),
accidentsSpecifications %>%
group\_by(hour) %>%
summarize(nb\_accidents = n\_distinct(Num\_Acc)),
by = 'hour'
) %>%
mutate(deathly\_accidents\_percentage = 100 \* (nb\_deathlyaccidents / nb\_accidents)) %>%
mutate(hour = factor(hour, levels = dayHours, labels = dayHoursLabels)) %>%
ggplot(aes(x = hour, y = deathly\_accidents\_percentage, group = 1)) +
geom\_col(fill = "#3e4c63") +
labs(
title = "Le pourcentage d'accidents mortels connait un pic entre minuit et 7h",
x = "Heure de la journée",
y = "Pourcentage d'accidents mortels"
) +
theme\_minimal()
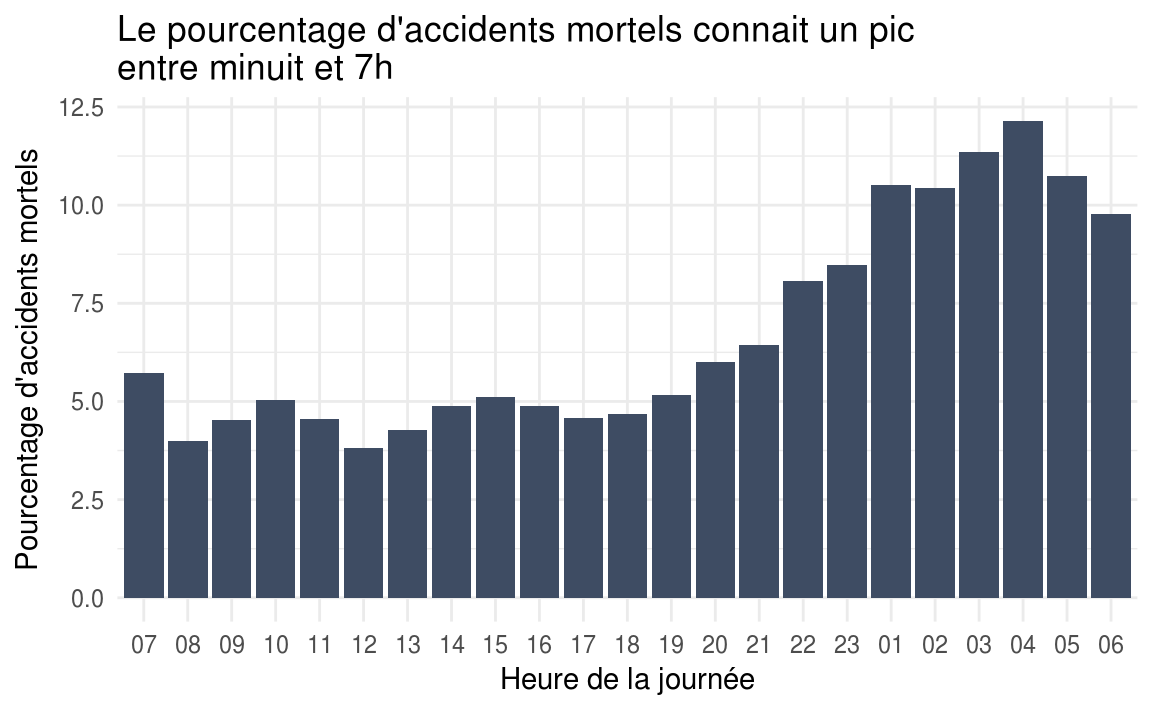
Le taux d’accidents mortels connait un pic entre minuit et 7h. Là aussi, nous pouvons émettre quelques hypothèses : visibilité moindre, fatigue, une plage horaire plus propice à des comportements à risques (retours de soirée, etc).
inner\_join(
accidentsUsers %>%
filter(grav == 2) %>%
group\_by(wday) %>%
summarize(nb\_deathly\_accidents = n\_distinct(Num\_Acc)),
accidentsSpecifications %>%
group\_by(wday) %>%
summarize(nb\_accidents = n()),
by = 'wday'
) %>%
mutate(wday = factor(wday, levels=c('Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat', 'Sun'), labels = c('Lundi', 'Mardi', 'Mercredi', 'Jeudi', 'Vendredi', 'Samedi', 'Dimanche'))) %>%
mutate(deathly\_accidents\_percentage = 100 \* (nb\_deathly\_accidents / nb\_accidents)) %>%
ggplot(aes(x = wday, y = deathly\_accidents\_percentage, group = 1)) +
geom\_col(fill = "#3e4c63") +
labs(
title = "Le pourcentage d'accidents mortels est plus important le week-end",
x = "Jour de la semaine",
y = "Pourcentage d'accidents mortels"
) +
theme\_minimal()
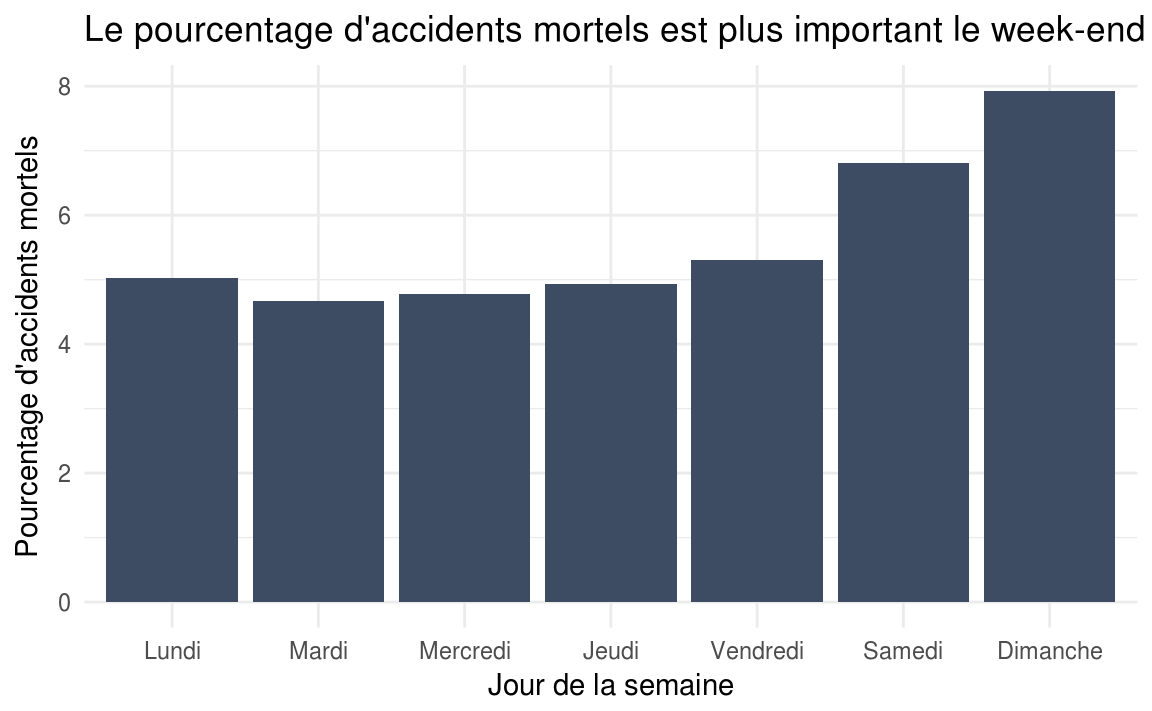
Là aussi, on peut imaginer que le plus fort taux d’accidents mortels durant le week-end est en partie dû au fait que cette période de la semaine est plus propice à des comportements à risques (retours de soirée, etc) mais il y a probablement d’autres facteurs qui entrent en jeu.
Les graphiques à prendre avec des pincettes : les accidents en fonction de l’âge et du sexe
accidentsUsers %>%
filter(grav == 2) %>%
mutate(age = year(now()) - an\_nais) %>%
group\_by(year, age) %>%
summarise(accidenteds\_number = n()) %>%
group\_by(age) %>%
summarize(accidenteds\_number = mean(accidenteds\_number)) %>%
ggplot(aes(x = age, y = accidenteds\_number, group = 1)) +
geom\_vline(aes(xintercept = 25), colour = "#ccd7ea", size = 1) +
geom\_vline(aes(xintercept = 35), size = 1, colour = "#ccd7ea") +
geom\_line(color = "#3e4c63", size = 1.5) +
labs(
title = "Il y a le plus de décès sur la route dans la tranche des 25 - 30 ans",
x = "Age",
y = "Nombre annuel moyen de morts sur la route en fonction de l'age"
) +
theme\_minimal()
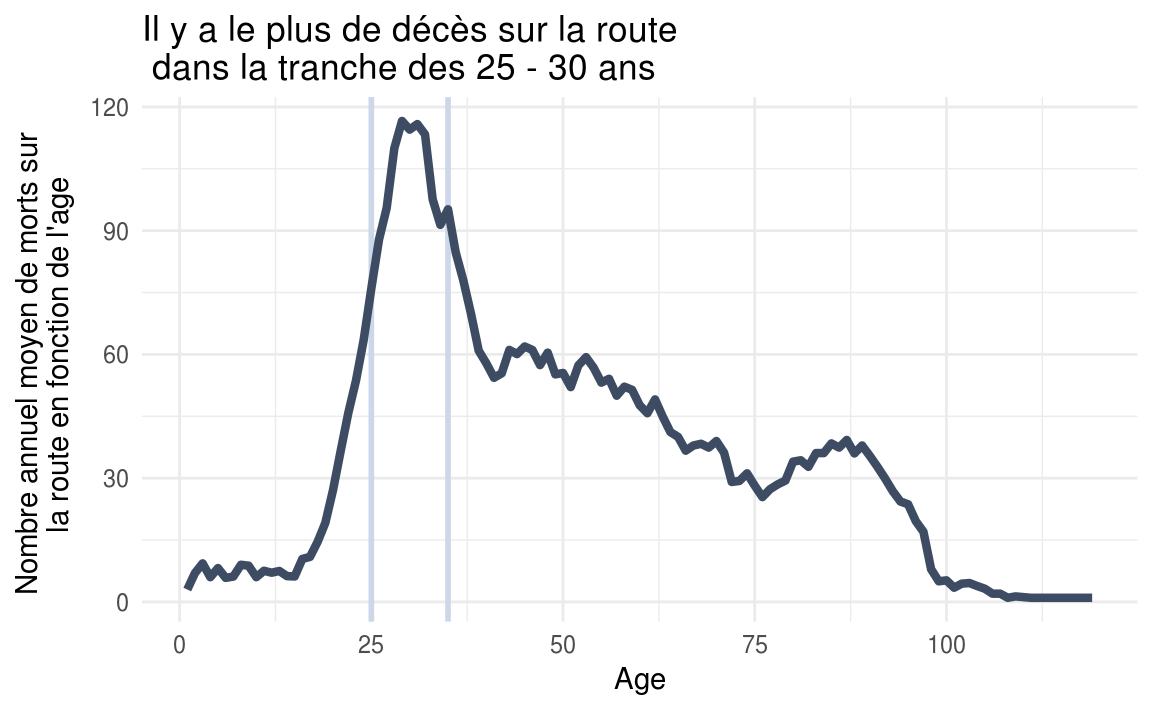
Le nombre de morts moyen est plus important dans la tranche des 25–30 ans. Attention, cela ne veut pas dire que cette tranche est plus à risque que les autres. En effet, on peut supposer que les usagers de cette tranche d’âge sont simplement les plus présents la route, d’où le nombre d’accidents plus important pour cette tranche.
accidentsUsers %>%
filter(catu == 1) %>%
group\_by(year, sexe) %>%
summarize(accidenteds\_number = n()) %>%
group\_by(sexe) %>%
summarize(accidenteds\_number = mean(accidenteds\_number)) %>%
mutate(sexe = factor(sexe, labels = c('Homme', 'Femme'))) %>%
ggplot(aes(x = sexe, fill = sexe, y = accidenteds\_number)) +
geom\_col() +
scale\_fill\_manual(values = c("#2b8cbe", "#fa9fb5")) +
guides(fill=FALSE) +
labs(
title = "Il y a moins d'accidents impliquant des femmes que des hommes",
x = "Sexe",
y = "Nombre annuel moyen d'accidents de la route par sexe"
) +
theme\_minimal()
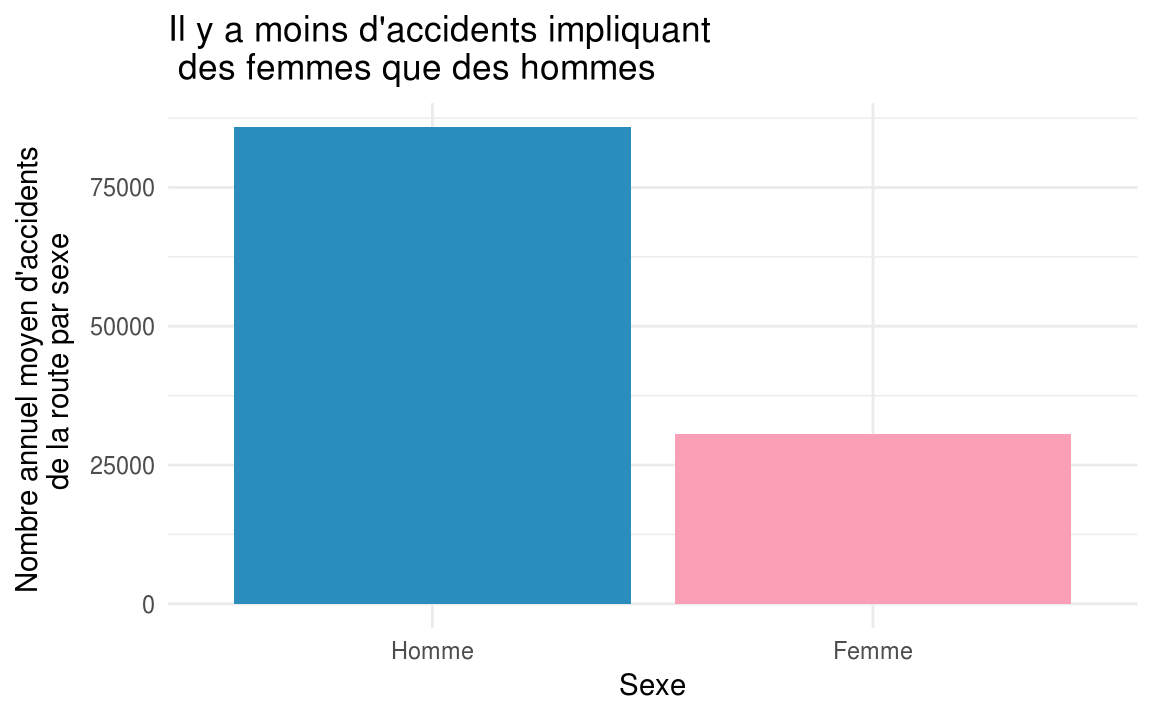
Là encore, attention, cela ne veut pas dire que les femmes conduisent mieux que les hommes. Les hommes sont peut-être simplement globalement plus présents sur la route que les femmes. On peut notamment trouver quelques informations à ce sujet dans une enquête de 2013 réalisée par l’Observatoire de la mobilité en Île-de-France.
Quelques cartographies …
deathsData <- accidentsSpecifications %>%
inner\_join(accidentsUsers) %>%
filter(grav == 2) %>%
filter(!is.na(lat) & !is.na(long) & lat != 0 & long != 0) %>%
mutate(lat = lat / 100000, long = long / 100000) %>%
filter(lat > 40 & long < 15) %>%
select(Num\_Acc, lat, long)ggplot(deathsData) +
geom\_polygon(data = map\_data("france"), aes(x=long, y = lat, group = group), fill = "#e5e5e5") +
geom\_point(deathsData, mapping = aes(x = long, y = lat), size = 0.1, color = "#3e4c63", alpha = 0.3) +
coord\_fixed(1.3) +
labs(
title = "Personnes décédées à la suite d'un accident de la circulation"
) +
theme\_void()

bikeAccidentsData <- accidentsSpecifications %>%
inner\_join(accidentsVehicles) %>%
inner\_join(accidentsUsers) %>%
filter(catv == '01') %>%
filter(dep == '750') %>%
mutate(lat = lat / 100000, long = long / 100000) %>%
mutate(grav = factor(grav, levels = c(1,4,3,2), labels = c('Indemne', 'Blessé léger', 'Blessé hospitalisé', 'Tué'))) %>%
select(Num\_Acc, grav, lat, long)ggmap(get\_map(location = c(lon = 2.3488, lat = 48.8534), source = "google", zoom = 12)) +
geom\_point(data = bikeAccidentsData, mapping = aes(x = long, y = lat, fill = grav), colour="#000000", size = 3, pch=21) +
labs(
title = "Les accidents de vélo à Paris selon la gravité",
fill = "Gravité"
) +
theme\_void() +
scale\_fill\_brewer(palette = "Reds", na.value = "#bababa") +
theme(legend.position="bottom")
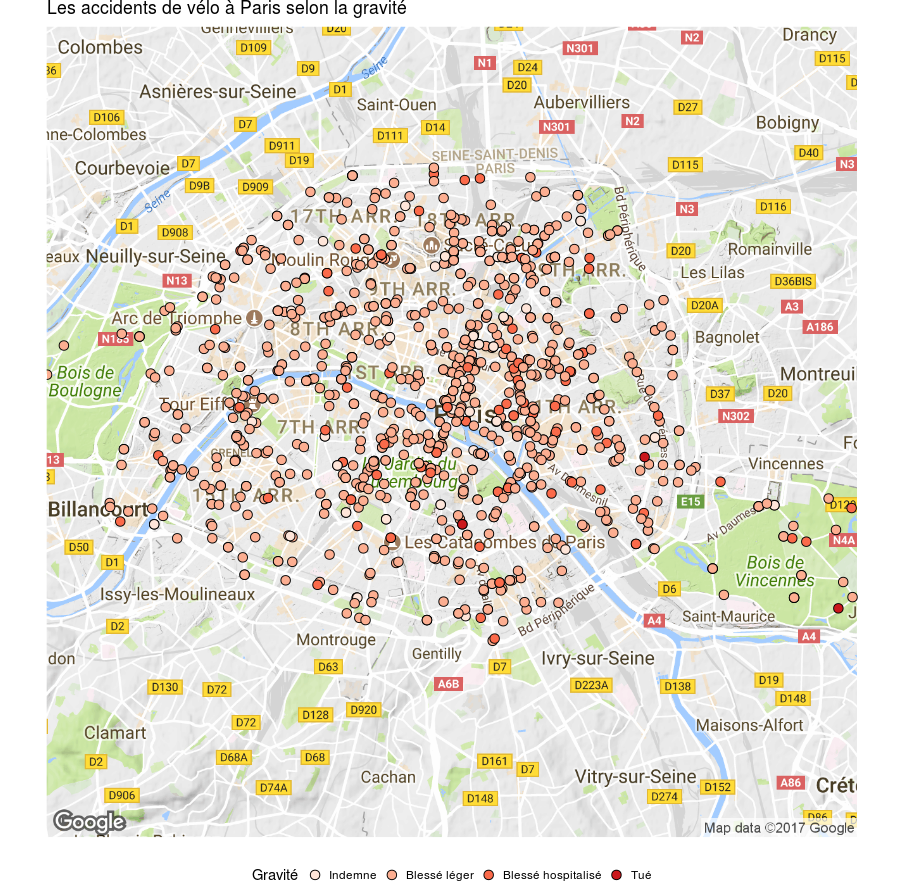
La première carte n’a que très peu d’intérêt puisque les zones où l’on retrouve le plus d’accidents correspondent bien sûr aux grands axes routiers ainsi qu’aux grandes villes. Il peut être en revanche intéressant de visualiser les accidents de la route par commune, voire par quartier pour identifier des axes dangereux par exemple.
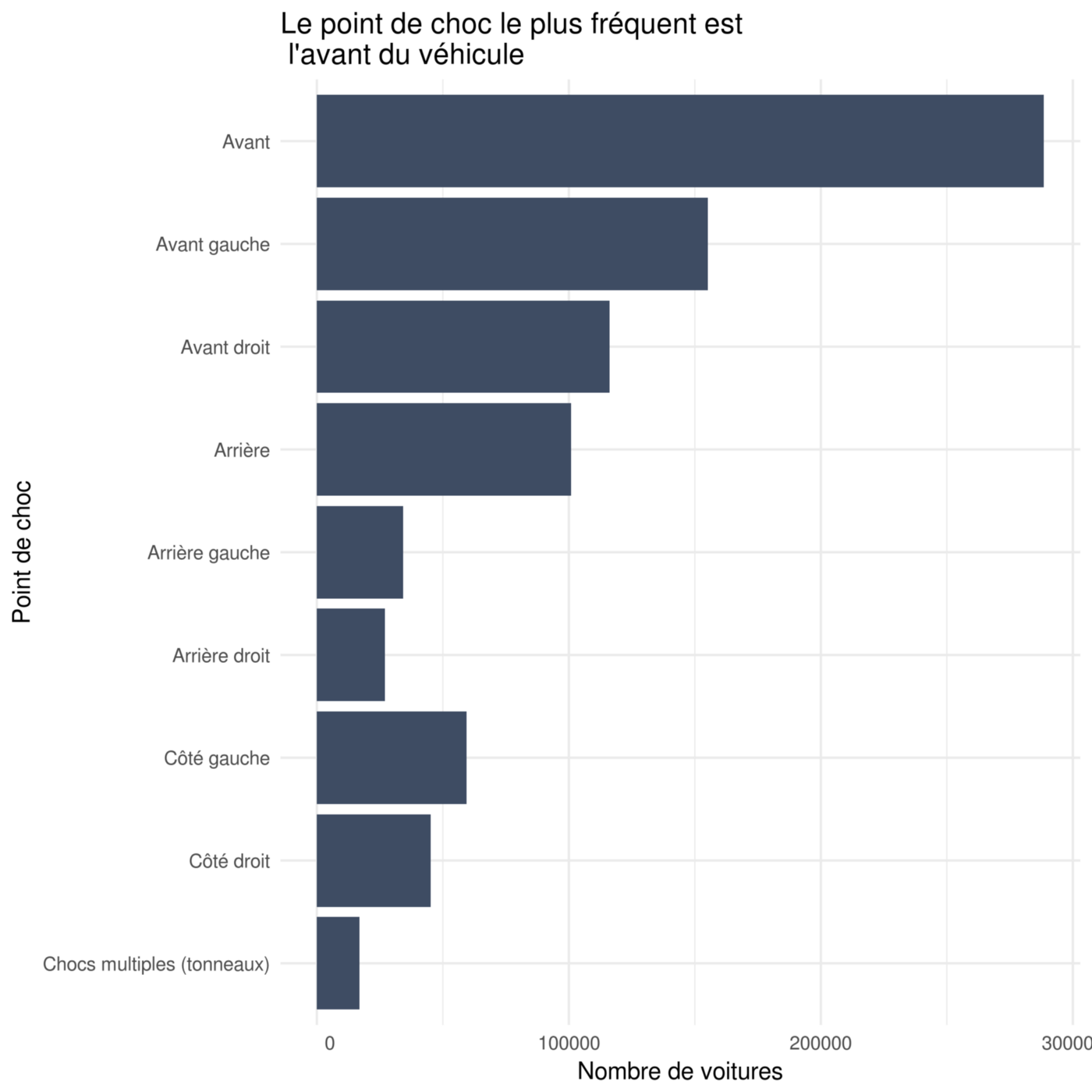
Points de chocs sur les voitures
accidentsVehicles %>%
filter(catv == '07') %>%
mutate(choc = factor(choc, levels = rev(c(1,3,2,4,6,5,8,7,9)), labels = rev(c('Avant','Avant gauche','Avant droit','Arrière','Arrière gauche','Arrière droit','Côté gauche','Côté droit','Chocs multiples (tonneaux)')))) %>%
group\_by(choc) %>%
summarize(accidenteds\_number = n()) %>%
filter(!is.na(choc)) %>%
ggplot(aes(x = choc, y = accidenteds\_number)) +
geom\_col(fill = "#3e4c63") +
labs(
title = "Le point de choc le plus fréquent est \\n l\\'avant du véhicule",
x = "Point de choc",
y = "Nombre de voitures"
) +
theme\_minimal() +
coord\_flip()