Mémorandum sur ce qu’il ne faut pas faire en Open Data
Vincent Brouté • September 28, 2017
dataCe billet a pour objectif d’ériger une courte (et donc forcément incomplète) liste des “don’t do this” à destination des producteurs de données ouvertes - C’est à dire toutes les choses qui peuvent ralentir ou compliquer (voire limiter) la réutilisation des données d’un point de vue technique.
Je vais m’appuyer pour cela sur un exemple réel, Datainfogreffe, qui est un cas d’école intéressant puisqu’on peut y trouver de nombreuses erreurs à éviter. Utilisateur de leurs données depuis quelques temps, je ressentais le besoin d’exprimer mon désarrois à travers un billet. Le but est de sensibiliser les fournisseurs de données sur l’importance de la qualité de la donnée (et pourquoi pas faire réagir Datainfogreffe par la même occasion …). En effet, à mon sens, faire de l’Open Data ne se limite pas simplement à mettre en ligne quelques CSV !
Infogreffe est un service de diffusion de l’information légale et officielle sur les entreprises. Datainfogreffe est la plateforme qui met à disposition ces données. Des accès payants aux APIs sont proposés via un système de crédits. Pour notre plus grand plaisir, une partie des données est cependant accessible en Open Data au travers de la plateforme OpenDataSoft. Ces jeux de données, annualisés, concernent notamment :
- Les créations d’entreprises
- Les radiations d’entreprises
- Les chiffres clés des entreprises (chiffre d’affaire, résultat net, effectif, etc)
[edit] Malgré les problèmes décelés dans les données ouvertes Datainfogreffe, elles n’en restent pas moins une source d’information très riche,utile et unique à propos des entreprises en France !
Décortiquons donc tout cela pour essayer d’identifier les problèmes relatifs à ces données.
La structure des jeux de données
Je ne m’attarderai pas sur le format des fichiers proposés par datainfogreffe : Les jeux sont en effet exportables en CSV et ce format me semble être tout à fait adapté car très simple à exploiter.
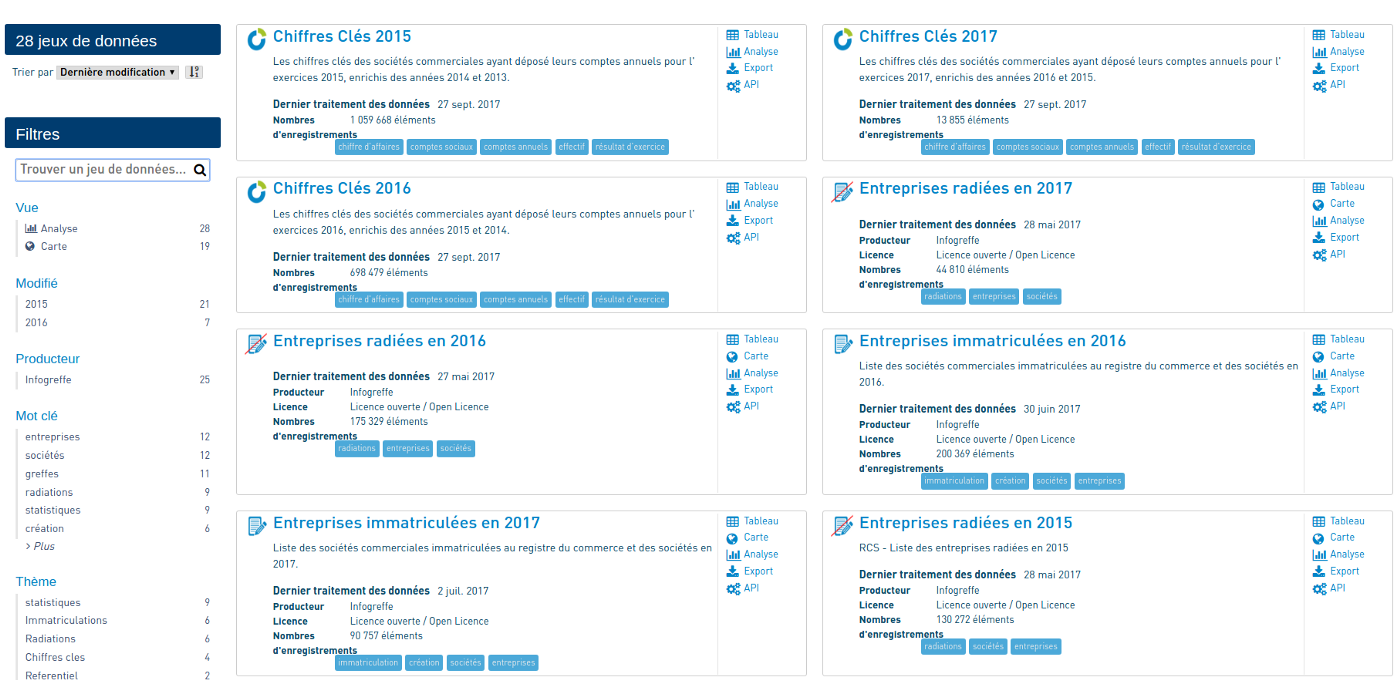
Pour chacune des 3 catégories de données, nous avons à disposition un fichier par année (de 2012 à 2017 pour les radiations et créations d’entreprises, et de 2014 à 2017 pour les chiffres clés).
Des colonnes disparaissent au fil des années
Dans le cas de jeux de données annualisées, une colonne qui existe sur l’année N devrait également exister sur l’année N+1. Autrement dit, on ne devrait pas voir de colonne disparaître au fil des années.
Sur Datainfogreffe, dans les fichiers des immatriculations d’entreprises, le secteur d’activité est renseigné de 2012 à 2015, mais ce n’est plus le cas à partir de 2016. Pas pratique si nous voulons réaliser une étude sur l’évolution des créations d’entreprises par secteur d’activité par exemple.
 Le secteur d’activité ? C’est has- been en 2016 !
Le secteur d’activité ? C’est has- been en 2016 !
Des colonnes sont créées au fil des années
Inversement, une colonne qui existe sur l’année N devrait exister sur l’année N-1. On peut toutefois modérer ce point car il peut s’agir de nouvelles variables qui n’existaient pas auparavant.
Par exemple, dans les fichiers des chiffres clés de Datainfogreffe, le code Insee du département de l’entreprise “Num. dept.” n’existe qu’à partir de l’année 2015.
 Les départements ça n’existait pas encore en 2014.
Les départements ça n’existait pas encore en 2014.
Des colonnes sont renommées au fil des années
Les variables ne devraient pas changer de nom entre un dataset de l’année N et celui de l’année N+1. Idéalement, les colonnes ne devraient pas non plus être réordonnées entre 2 années.
Chez Datainfogreffe, il y a pas mal de libertés concernant ce point : selon les années, on retrouve du “Code activité (APE)” et du “Code APE”, du “Date immatriculation” et du “Date d’immatriculation”, du “Date radiation” et du “Date de radiation”, etc. On comprend facilement que cela peut être un gros frein pour automatiser l’import de toutes les années de données par exemple.
 Et si on changeait le nom de la colonne de temps en temps ?
Et si on changeait le nom de la colonne de temps en temps ?
Le nommage des colonnes n’est pas consistant
Le nommage des colonnes d’un même dataset devrait être consistant : par exemple, si une colonne est au singulier, les autres devraient l’être également. Si une colonne est écrite en snake_case, toutes les colonnes devraient respecter ce format.
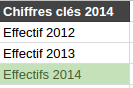
On peut illustrer ce point avec le jeu de données 2014 des chiffres clés de Datainfogreffe, dans lequel on peut trouver une colonne Effectif 2013et une colonne Effectifs 2014.
 Aller, en 2014 on va mettre du pluriel pour casser la monotonie
Aller, en 2014 on va mettre du pluriel pour casser la monotonie
Les datasets contiennent des colonnes “parasites”
J’entends par colonne parasite, des colonnes dont le nommage ou la documentation ne permettent pas de savoir ce qu’elles contiennent.
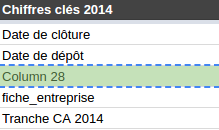
Sur Datainfogreffe, on peut par exemple trouver une colonne intitulée test1 dans les chiffres clés 2016 & 2017, ou encore une colonne Column 28 dans les chiffres clés 2014. Je vous mets au défi de m’expliquer leur contenu.
 Bonjour Column 28, tu fais quoi dans la vie ?
Bonjour Column 28, tu fais quoi dans la vie ?
[edit] Suite à la publication de mon article, Datainfogreffe a nettoyé les différents jeux de données de ces colonnes “parasites”.
Les datasets annualisés contiennent plusieurs années de données
Les jeux de données peuvent contenir plusieurs années de données à condition qu’il y ait une variable année clairement identifiée dans le jeux de données — Chaque ligne de données étant liée à une et une seule année. Une alternative moins propre est de construire autant de colonnes qu’il y a d’années pour une variable donnée.
Dans le cas où les fichiers sont annualisés (un fichier par année), on ne s’attend naturellement pas à retrouver plusieurs années de données au sein d’un même dataset.
Chez Datainfogreffe, dans les fichiers des chiffres clés, nous retrouvons l’année N, mais aussi l’année N-1 et l’année N-2.
Par exemple, le fichier des chiffres clés 2014 contient également les données des années 2013 et 2012. On y trouve ainsi les variables CA 2012, CA 2013, CA 2014.
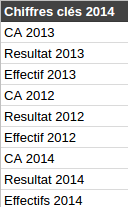 Dans le fichier 2O14, on va rajouter 2013 et 2012 pour que ce soit bien complet
Dans le fichier 2O14, on va rajouter 2013 et 2012 pour que ce soit bien complet
Comme chaque dataset reprend les données des années N-1 et N-2 , on a donc une duplication d’informations entre les fichiers. Par exemple, le chiffre d’affaire 2015 sera présent dans les fichiers 2015, 2016 et 2017.
Vérifions avec R que nous avons bien le même chiffre d’affaire 2015 dans les fichiers 2015 et 2016 :
library(tidyverse)mainIndicators2015 <- read\_csv2('chiffres-cles-2015.csv')
mainIndicators2016 <- read\_csv2('chiffres-cles-2016.csv')mainIndicators <- inner\_join(mainIndicators2015, mainIndicators2016, by = 'Siren') %>%
select(Siren, \`CA 1.x\`, \`CA 2.y\`)mainIndicatorsmainIndicators %>%
filter(\`CA 1.x\` != \`CA 2.y\`)\# A tibble: 615,482 x 3
Siren \`CA 1.x\` \`CA 2.y\`
<chr> <int> <int>
1 349735860 225480 225480
2 349737460 44630 44630
3 349738856 348060 348060
4 349742130 NA NA
5 349745414 NA NA
6 349746420 707978 707978
7 349746529 1017859 1017859
8 349748442 NA NA
9 349749911 NA NA
10 349751081 12755788 12755788
\# ... with 615,472 more rows\# A tibble: 6,486 x 3
Siren \`CA 1.x\` \`CA 2.y\`
<chr> <int> <int>
1 349805457 2805204 2805000
2 325165579 190968 190000
3 324925296 867013 867000
4 324977735 1537350 1537
5 325165579 190968 190000
6 325184513 1796937 1796000
7 324042761 367849 652223
8 324716026 1442909 1442000
9 324716141 4000171 4000000
10 301670816 394720 395
\# ... with 6,476 more rows
Le résultat est sans appel : nous avons 6 486 entreprises sur 615 482 pour lesquelles nous n’avons pas le même CA 2015 ! Et certaines différences sont … saisissantes : on passe de 1 537 350€ à 1 537€ de CA 2015 entre les deux fichiers. Hum, on dirait qu’il y a eu comme une division par 1 000 entre les deux ... Lorsqu’on est face à de tels cas, quel fichier “croire” ?
7 mois plus tard, ces bizarreries n’ont toujours pas été corrigées ou expliquées par Datainfogreffe.
Les colonnes ne permettent pas d’identifier l’année correspondant aux valeurs
Si vous choisissez de stocker plusieurs années dans un même fichier dans des colonnes différentes, il faut que le nom de la colonne permette d’identifier clairement l’année.
Sur les fichiers des chiffres clés postérieurs à 2015, nous ne savons même pas à quelles années correspondent les colonnes puisque l’on a des nommages du type : “CA 1”, “CA 2”, “CA 3”, pratique …
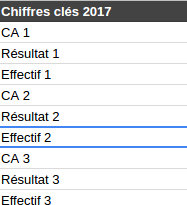 C’est quelle année dans CA 2 ? Je sais pas j’ai fait un random pour brouiller les pistes.
C’est quelle année dans CA 2 ? Je sais pas j’ai fait un random pour brouiller les pistes.
On mélange les choux et les carottes …
Un jeu de données devrait contenir uniquement des données relatives à la thématique dudit jeu. Logique, non ?
Pas pour Datainfogreffe. En effet, on peut trouver dans les radiations et les immatriculations 2017 des informations … sur les chiffres clés (CA, résultat, effectif). Ce n’est pas comme si ces variables étaient déjà présentes en triple dans les datasets des chiffres clés eux-mêmes.
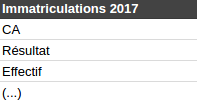 Qu’est-ce-que tu fais là ?
Qu’est-ce-que tu fais là ?
D’ailleurs, allons vérifier ce que contient la colonne CA dans le dataset des immatriculations 2017 :
newCompanies2017 <- read\_csv2('entreprises-immatriculees-2017.csv')
newCompanies2017 %>%
filter(!is.na(CA)) %>%
select(Siren, CA)\# A tibble: 1 x 2
Siren CA
<int> <chr>
1 399323914 5046
Étrange, il n’y a en tout et pour tout qu’une seule entreprise avec un CA non vide sur les 129 236 entreprises que compte le fichier des entreprises immatriculées en 2017.
Des colonnes sont en doublon
Une colonne ne devrait apparaître qu’une seule fois avec un même nom dans un fichier, il ne devrait pas y avoir de doublons.
Sur Datainfogreffe, on peut par exemple trouver ce problème dans les radiations d’entreprises 2015, où nous avons le droit à 2 colonnes Géolocalisation, mais aussi 2 colonnes Date de radiation.
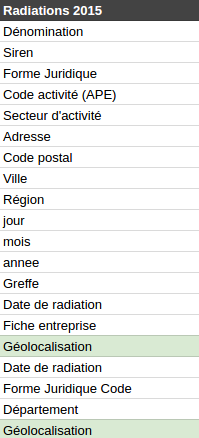 Parce qu’un homme averti en vaut deux
Parce qu’un homme averti en vaut deux
closedCompanies2015 <- read\_csv2('entreprises-radiees-2015.csv') %>%
select(Siren, \`Géolocalisation\`, \`Géolocalisation\_1\`, \`Date de radiation\`, \`Date de radiation\_1\`)
closedCompanies2015 %>%
filter(\`Géolocalisation\` != \`Géolocalisation\_1\`)closedCompanies2015 %>%
filter(\`Date de radiation\` != \`Date de radiation\_1\`)\# A tibble: 0 x 5
\# ... with 5 variables: Siren <int>, Géolocalisation <chr>, Géolocalisation\_1 <chr>, Date de radiation <date>, Date de radiation\_1 <date>\# A tibble: 0 x 5
\# ... with 5 variables: Siren <int>, Géolocalisation <chr>, Géolocalisation\_1 <chr>, Date de radiation <date>, Date de radiation\_1 <date>
Au moins, les valeurs dans les colonnes en doublon sont identiques.
La même information est présente sous différents formats
Une information ne devrait être présente qu’une seule fois dans un jeu de données, sous sa forme la plus facile à exploiter. Il est inutile d’avoir la même information sous différents formats.
Datainfogreffe illustre très bien ce point dans les radiations d’entreprises 2015 où nous avons une colonne Date de radiation mais également 3 colonnes jour, mois, annee représentant la même information. C’est parfaitement inutile, et cela augmente la taille des fichiers pour rien.
Parce qu’on ne sait jamais, on va vérifier la cohérence entre ces deux variables avec R :
closedCompanies2015 <- read\_csv2('/home/vbroute/Téléchargements/entreprises-radiees-2015.csv') %>%
select(Siren, \`Date de radiation\`, jour, mois, annee)closedCompanies2015 %>%
mutate(
date1 = ymd(\`Date de radiation\`),
date2 = ymd(paste(annee, mois, jour))
) %>%
filter(date1 != date2)\# A tibble: 46,407 x 7
Siren \`Date de radiation\` jour mois annee date1 date2
<int> <date> <int> <int> <int> <date> <date>
1 409955838 2015-08-07 8 7 2015 2015-08-07 2015-07-08
2 422861054 2015-08-07 8 7 2015 2015-08-07 2015-07-08
3 431905512 2015-08-07 8 7 2015 2015-08-07 2015-07-08
4 433752623 2015-08-07 8 7 2015 2015-08-07 2015-07-08
5 435198932 2015-08-07 8 7 2015 2015-08-07 2015-07-08
6 437993900 2015-08-07 8 7 2015 2015-08-07 2015-07-08
7 437933278 2015-08-07 8 7 2015 2015-08-07 2015-07-08
8 441522828 2015-08-07 8 7 2015 2015-08-07 2015-07-08
9 444694061 2015-08-07 8 7 2015 2015-08-07 2015-07-08
10 452440704 2015-08-07 8 7 2015 2015-08-07 2015-07-08
\# ... with 46,397 more rows
Bingo : il y a 46 407 lignes sur 130 272 dans les quelles les dates ne sont pas les mêmes selon qu’on exploite la colonne Date de radiation ou les colonnes jour, mois et annee . Cela ressemble à une inversion entre les jours et les mois dans l’une des deux variables … mais laquelle ?
La qualité des données
Pour proposer un jeu de données de bonne qualité, il faut des données de bonne qualité, vérifiées, validées, etc. Les données étant ouvertes, elles sont susceptibles d’être transformées et rediffusées par de nombreux utilisateurs — qui n’ont pas forcément envie de diffuser des informations erronées.
Nous avons déjà repéré précédemment de nombreuses incohérences au niveau des chiffres clés et des dates de radiations et nous pouvons encore continuer un peu, pour le plaisir.
Par exemple, les coordonnées géographiques des entreprises sont complètement fausses, elles ne correspondent pas à la localisation de l’entreprise, mais à la localisation du centre de la commune d’implantation. Faisons le test sur les entreprises Rennaises radiées en 2015 :
closedCompanies2015 <- read\_csv2('entreprises-radiees-2015.csv')%>%
select(Siren, \`Géolocalisation\`, \`Code postal\`)closedCompanies2015 %>%
filter(\`Code postal\` == '35000')\# A tibble: 355 x 3
Siren Géolocalisation \`Code postal\`
<int> <chr> <chr>
1 384982047 48.1116364246, -1.6816378334 35000
2 788545127 48.1116364246, -1.6816378334 35000
3 504870775 48.1116364246, -1.6816378334 35000
4 791212269 48.1116364246, -1.6816378334 35000
5 523084986 48.1116364246, -1.6816378334 35000
6 788994747 48.1116364246, -1.6816378334 35000
7 479507808 48.1116364246, -1.6816378334 35000
8 511016297 48.1116364246, -1.6816378334 35000
9 403610736 48.1116364246, -1.6816378334 35000
10 530015577 48.1116364246, -1.6816378334 35000
\# ... with 345 more rows
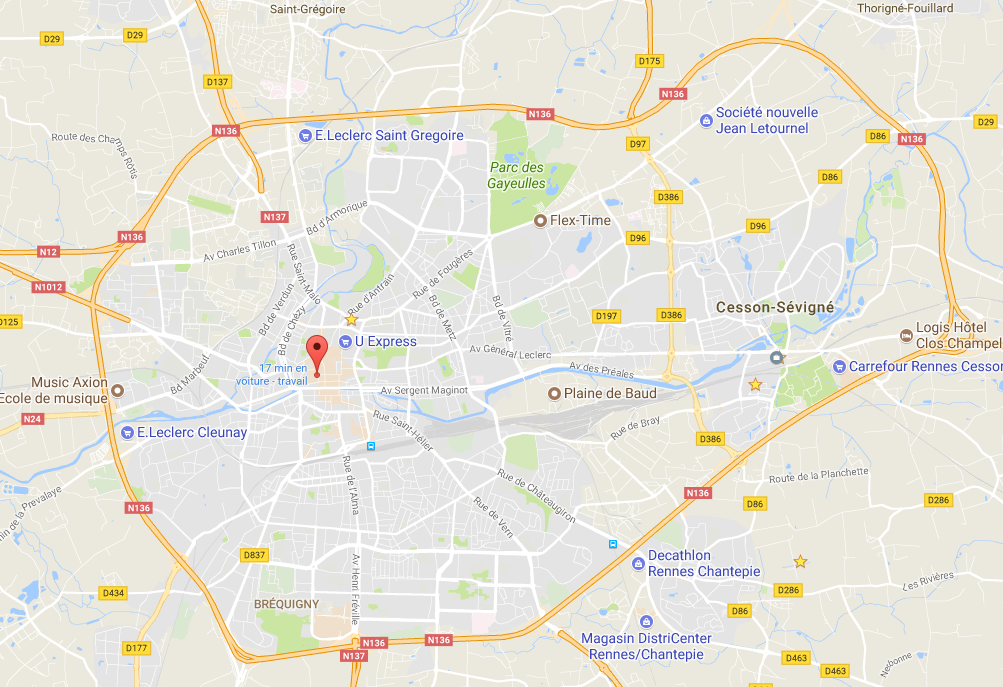
D’après Datainfogreffe, les 355 entreprises radiées en 2015 à Rennes sont toutes situées au point de coordonnées (48.1116364246, -1.6816378334). Ils devaient être un peu à l’étroit …
Toujours dans le même jeu de données, allons faire un tour du côté des codes postaux, pour voir ce qu’il s’y cache. Un code postal contient 5 chiffres, regardons si il y en a qui dérogent à cette règle :
closedCompanies2015 <- read\_csv2('entreprises-radiees-2015.csv')%>%
select(Siren, \`Code postal\`)closedCompanies2015 %>%
filter(str\_length(\`Code postal\`) != 5)
\# A tibble: 126 x 2
Siren \`Code postal\`
<int> <chr>
1 529857021 FL 333
2 790120745 3530
3 398308874 WIMODD
4 407777010 1030
5 805013141 2035
6 448367599 4070
7 794245241 .
8 NA SOISSONS
9 804722460 1140
10 484651443 8050
\# ... with 116 more rows
Visiblement, je n’ai pas la même notion de code postal que Datainfogreffe. Je vais m’arrêter là, mais si vous fouillez un peu, vous trouverez très certainement de nombreuses autres bizarreries dans ces données.
De telles erreurs dans des données publiques sont d’autant plus graves qu’elles concernent des entreprises. La diffusion de fausses données peut en effet leur porter préjudice. Imaginez que l’on publie un CA divisé par 1000 pour une entreprise ? Ou bien qu’on indique qu’une entreprise est fermée alors que ce n’est pas le cas ? (si vous cherchez bien, vous en trouverez dans le fichier des radiations 2017 …).
La mise à jour des données
Un jeu de données de bonne qualité est un jeu de données qui est mis à jour régulièrement. Sur des données annualisées, on s’attend à voir une mise à jour par an.
L’intention de Datainfogreffe est louable dans le sens où les jeux de données de l’année courante sont mis à jour au fil de l’année. Cela devient problématique lorsque ces mises à jour s’arrêtent en cours d’année … A l’heure où j’écris ces lignes (26 septembre 2017), le dataset des radiations 2017 n’a pas été mis à jour depuis le mois de mai, et celui des immatriculations 2017 ne l’a pas été depuis le mois de juillet.
[edit] Après vérification, il apparaît que les données des radiations et des immatriculations 2017 sont bien mises à jour régulièrement. En revanche, le site ainsi que l’API indiquent des dates de mises à jour totalement dépassées pour ces 2 jeux de données.
Les évolutions de structure dans le temps
La structure d’un jeu de données Open Data ne devrait pouvoir être modifiée qu’à condition que les-dites modifications soient extrêmement bien documentées et que les utilisateurs en soit informés.
En effet, lorsque l’on crée une étude basée sur un ou plusieurs jeux de données, il est fort irritant de ré-exécuter le code quelques semaines plus tard et de constater que toute la structure des fichiers a changé — et qu’il faut jouer aux devinettes pour comprendre les modifications qui ont pu être faites.
Du côté de datainfogreffe, je ne compte plus les modifications de structures en tout genre. J’y ai même repéré des suppressions de données : il y a quelques temps encore, nous avions accès aux chiffres clés de 2011, ce qui n’est plus le cas aujourd’hui.
La documentation
La documentation qui doit accompagner les données est bien entendu indispensable. Vous trouverez un bon exemple de documentation du côté de la base SIRENE qui se trouve être vraiment complète : description de chaque champs, valeurs possibles, typage des valeurs, longueur, etc.
A l’inverse, pour ce qui est de Datainfogreffe, la documentation des jeux de données est pour ainsi dire quasi inexistante.
 La doc ? C’est pour les nazes !
La doc ? C’est pour les nazes !
L’ (entre-)aide proposée aux utilisateurs de données
En plus d’une bonne documentation, il est important de proposer un espace public (système de commentaires, forum, etc) sur lequel les utilisateurs de données peuvent poser des questions aux producteurs (ou aux autres utilisateurs). L’intérêt d’un espace d’échange public par rapport à un simple formulaire de contact est bien sûr que les réponses soient partagées et consultables par tous.
Malheureusement, sur Datainfogreffe, seul un formulaire de contact est disponible. (quelqu’un a-t’il déjà reçu une réponse ?)
Pour conclure …
L’avènement de l’Open Data permet aujourd’hui d’avoir accès à une abondance de données ouvertes en tout genre, sur de très nombreuses thématiques, et c’est très bien.
Néanmoins, pour que cette masse de données puisse être comprise et exploitée par les utilisateurs (sans quoi elles ne servent à rien), la qualité doit être au centre des attentions des producteurs.
La qualité des données est d’autant plus importante lorsque des informations erronées peuvent porter directement atteinte aux entités concernées (entreprises, communes, écoles, etc). Les producteurs ne doivent donc pas perdre de vue que leurs données sont susceptibles d’être re-publiées dans de nombreux formats, via de nombreux canaux et dans des contextes très variés.
J’ai l’impression qu’avec le temps, cela va globalement dans le bon sens mais il faut continuer à accompagner, former et outiller les fournisseurs afin que la qualité des données ouvertes continue de s’améliorer.
Par exemple, la base SIRENE, ouverte en début d’année 2017 est plutôt de très bonne qualité à mon sens. Les structures des fichiers sont claires et bien documentées, les mises à jour (bi-annuelles, mensuelles et quotidiennes) sont suivies, il y a un espace d’échange accessible via la plateforme data.gouv.fr , etc.
J’invite donc Datainfogreffe à embrasser la bonne voie de l’évolution de l’Open Data en corrigeant les nombreux problèmes que j’ai pu déceler dans les jeux de données afin d’aboutir à une source d’information riche et de qualité.