Tutorial : Turn your data into narratives using TextGenerator, Wikidata and Google Spreadsheet
Vincent Brouté • September 13, 2016
phpThis tutorial shows you how to generate narratives from data in a few steps using the TextGenerator, Wikidata and Google Spreadsheet.
The TextGenerator is at first a PHP package that allows to produce texts from data by using a template in which functions calls can take place.
In addition to this package, an add-on for Google Spreadsheet is available and allows to generate narratives directly from a Spreadsheet, through a handy interface. We will use the Spreadsheet Add-on for the tutorial.

In a nutshell, the TextGenerator takes as input a dataset and a template, and outputs the texts generated from them. A lot of useful functions can be used within the template : you can shuffle sentences, pick up a random word from a list, condition the display of some parts from your narrative, loop on sub-data, assign variables, etc …
It aims to produce narratives that seem natural from datasets of any sizes.
For the tutorial, we will take some actors data from Wikidata and push them into a Google Spreadsheet document. Then, we will install the TextGenerator Add-on for Spreadsheet and use it to generate the narratives from our data. Let’s go !
Retrieve the data from Wikidata

Wikidata is a collaborative knowledge base launched by the Wikimedia Foundation in 2012. It aims to store structured data that come mainly from Wikipedia. It includes some other sources of data like Freebase, that has been shut down in May 2016.
The interesting thing is that Wikidata relies on Linked Data standards. In a nutshell, it allows you to retrieve RDF datasets. RDF is the graph data model of the Linked Data, in which the data are structured into “subject - predicate - object” triples, and offers several serializations such as RDF-XML, N3, Turtle, etc. Moreover, you can easily query the data with the available endpoint by using SPARQL language. C_urrently, Wikidata stores 1,262,008,154 triples._
For your information, DBPedia is also a great public source of data that also provides a SPARQL Endpoint_. An interesting benefit from DBPedia over Wikidata is that the predicates are human readable. On the other hand, the data seems to be more messy than in Wikidata. I have experienced it when querying data from actors, where the birthplaces were sometimes objects, sometimes literals strings for instance. C_urrently_, DBPedia stores 438,038,621 triples._
Let’s run our SPARQL query on Wikidata endpoint in order to retrieve our data for film actors. For the tutorial, we will retrieve their name, gender, country, demonym, birth place, birth date, number of children and the awards won. You just have to copy/paste the query below into the field :
PREFIX wdt: <[http://www.wikidata.org/prop/direct/](http://www.wikidata.org/prop/direct/)\>
PREFIX wd: <[http://www.wikidata.org/entity/](http://www.wikidata.org/entity/)\>
PREFIX pq: <[http://www.wikidata.org/prop/qualifier/](http://www.wikidata.org/prop/qualifier/)\>
PREFIX rdfs: <[http://www.w3.org/2000/01/rdf-schema#](http://www.w3.org/2000/01/rdf-schema#)\>
PREFIX p: <[http://www.wikidata.org/prop/](http://www.wikidata.org/prop/)\>
SELECT
(MAX(?label) AS ?label)
(MAX(?genderLabel) AS ?gender)
(MAX(?countryLabel) AS ?country)
(MAX(?demonym) AS ?demonym)
(MAX(?birthPlaceLabel) AS ?birthPlace)
(MAX(?birthCountryLabel) AS ?birthCountry)
(MAX(?birthDate) AS ?birthDate)
(MAX(?numberOfChildren) AS ?children)
(CONCAT('\[', GROUP\_CONCAT(DISTINCT ?awardData; SEPARATOR = ','), '\]') AS ?awards)
(COUNT(?awardData) AS ?awardsCount)
WHERE {
?s wdt:P106 wd:Q10800557 . #occupation : filmActor
?s rdfs:label ?label . FILTER(lang(?label) = 'en') .
?s wdt:P21 ?gender .
?gender rdfs:label ?genderLabel FILTER(lang(?genderLabel) = 'en') .
?s wdt:P569 ?birthDate .
?s wdt:P27 ?country . FILTER(?country != wd:Q403) .
?country rdfs:label ?countryLabel FILTER(lang(?countryLabel) = 'en') .
?country wdt:P1549 ?demonym FILTER(lang(?demonym) = 'en') .
?s wdt:P19 ?birthPlace .
?birthPlace rdfs:label ?birthPlaceLabel FILTER(lang(?birthPlaceLabel) = 'en') .
?birthPlace wdt:P17 ?birthCountry .
?birthCountry rdfs:label ?birthCountryLabel FILTER(lang(?birthCountryLabel) = 'en') .
OPTIONAL {?s wdt:P1971 ?numberOfChildren} .
?s p:P166 ?award .
?award pq:P585 ?awardDate .
?award pq:P1686 ?awardMovie .
?awardMovie rdfs:label ?awardMovieLabel FILTER(lang(?awardMovieLabel) = 'en') .
BIND(CONCAT('{"movielabel":"', ?awardMovieLabel, '","movieyear":"', xsd:string(YEAR(?awardDate)), '"}') AS ?awardData)
}
GROUP BY ?s
LIMIT 100
Note : I have excluded Serbian actors in the query to avoid a weird encoding issue that break some lines in the CSV file, I will try to find a better fix …
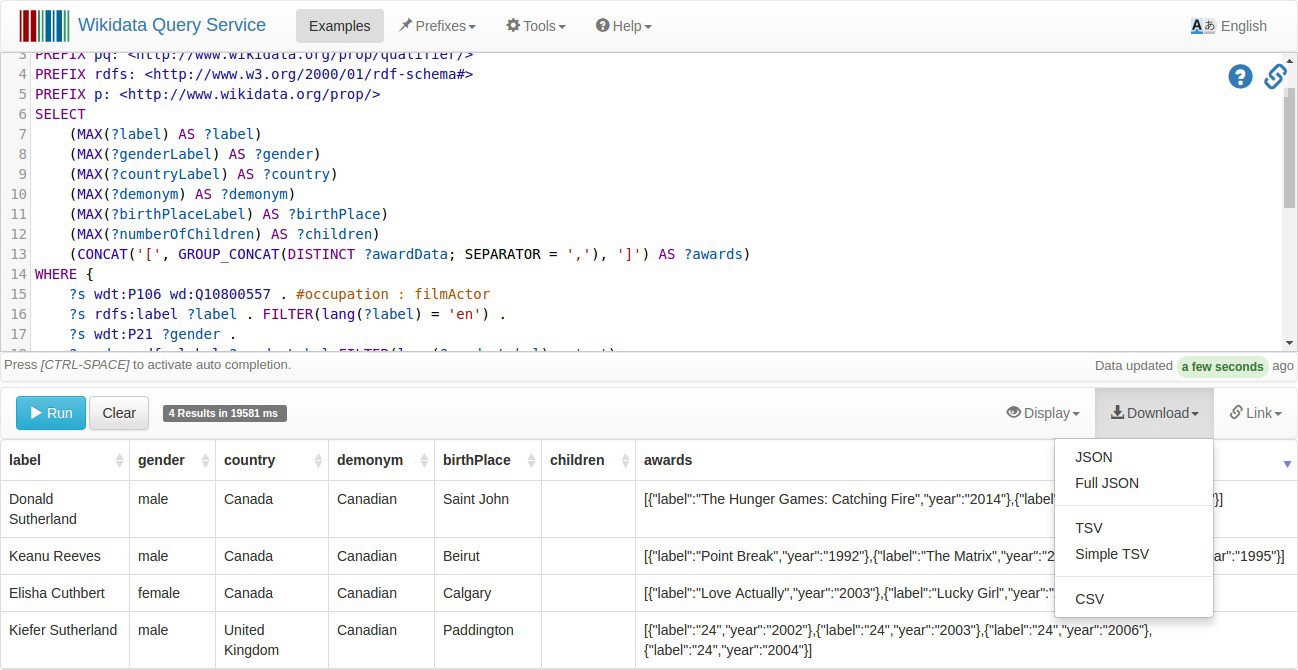
After running the query, you can download the result as CSV dataset by clicking on “Download” > “CSV”. Then, you can import your CSV dataset into a new Spreadsheet Document on Google Drive.
Install the plugin and generate the narratives
Note : The spreadsheet plugin is no longer available.
In order to install the TextGenerator add-on, you just have to go to this link and click on the “install” button.
As an alternative way, from a spreadsheet document, you can go to Add-ons > Download add-ons, search for “TextGenerator” and install it.
Once it has been installed, the first step is to click on the column where you want the narratives to be inserted in your Spreadsheet. With our sample actors dataset, we will generate them into the column K. Then, you can run the add-on by clicking on add-ons > TextGenerator > Generate Texts, it will open a sidebar :
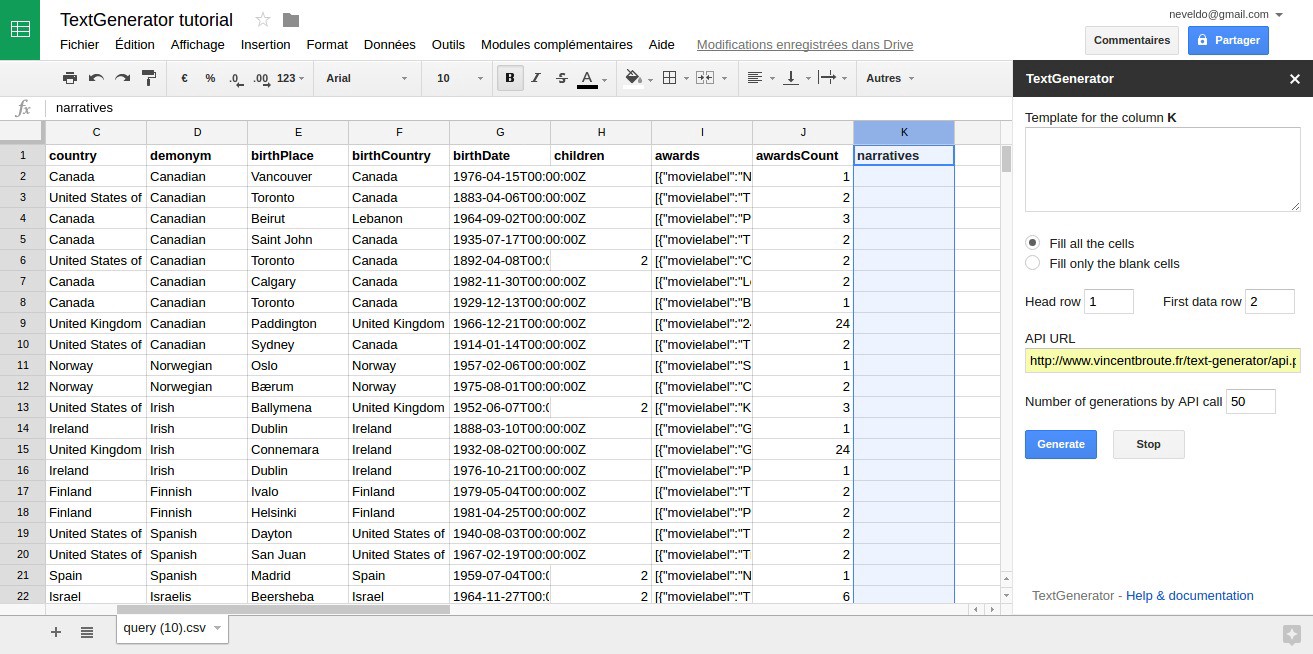
All the parameters including the template will be saved for the current active column so you can retrieve them when you re-open your document. Moreover, it allows you to build multiple templates on multiple columns.
The fields from the sidebar are self-explanatory and come with default values, exept for the template. Clicking on the template field will open a larger editor :
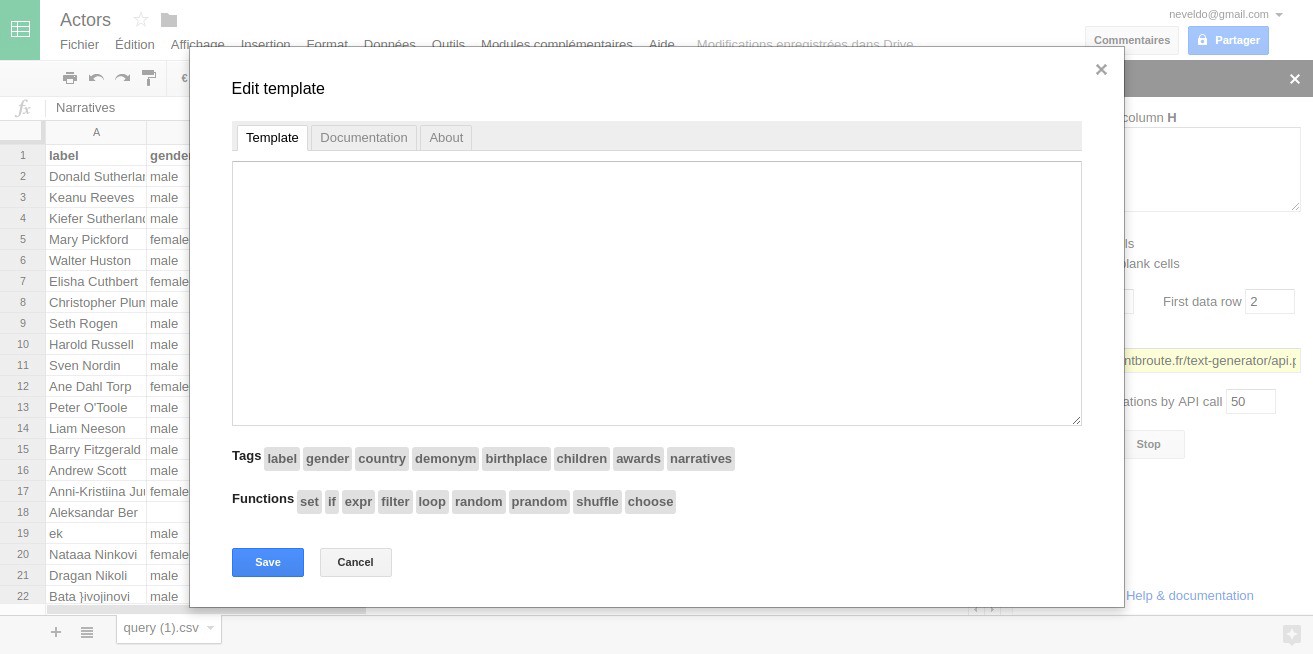
The template field could be improved in the future by adding a preview tab and syntatic coloration
There are some tabs in which you can find the template editor and the complete documentation of TextGenerator. Below the template field, there are shortcut buttons to insert tags or function calls within your template.
A tag is like a variable, they allow to insert values from the dataset within the generated narratives. They are named after the head row of the sheet. For instance, the tag “@label” will be replaced by “Donald Sutherland” value for the narrative related to the first row in our dataset.
A function call allows you to provide some intelligence to your template. For instance, you can shuffle some sentences, output a random word from a list, add conditions in order to display or hide some parts of the text, etc. All the available functions are documented within the “Documentation” tab.
Here is our sample template, it is far from perfect, but feel free to improve it :
#set{ @he|#if{ @gender == 'male'|He|She}};;
#set{ @his|#if{ @gender == 'male'|his|her}};;
#set{ @demonym\_first\_letter|#filter{substring| @demonym|0|1}};;
#set{ @demonym\_prefix|#if{ @demonym\_first\_letter in \['A', 'E', 'I', 'O', 'U', 'Y'\]|an|a}};;
#set{ @formated\_birthdate|#filter{date| @birthdate|Y-m-d\\T00:00:00\\Z|F d, Y}};;
#set{ @age|#expr{#filter{timestamp|Y} - #filter{date| @birthdate|Y-m-d\\T00:00:00\\Z|Y}}};; @label is @demonym\_prefix @demonym #if{ @gender == 'male'|actor|actress} born in @birthplace, @birthcountry on @formated\_birthdate. ;;
#shuffle{ |;;
#random{Throughout|During|All along} @his career in @country, @label has won @awardscount #random{award|price|trophy}#if{ @awardscount > 1|s} for #loop{ @awards|\*|false|, | and | @movielabel in @movieyear}.|;;
@he is #random{now|} @age years old#if{ @children > 0| and has @children #if{ @children > 1|children|child}}.;;
}
Once we have set the template, the last step is to press the button “Generate” to get our narratives :

Go further with TextGenerator
TextGenerator is not only an Add-on for Spreadsheet, but it is also a PHP Package available on packagist. You can also fork the sources on GitHub. In that way, you can include it in your projects in order to do a lot more things that what have been described in this short tutorial !
If you encounter a bug or an issue, feel free to report it in the GitHub issues. At last, as this is an Open Source project, you are of course welcome to contribute !